Monday, September 23, 2013
How to script sql server jobs and migrate to another server ....
1. First of all open SSMS and connect to your sql server from where you want to copy jobs.
2. Then click on View on menu bar and then select Object Explorer Details
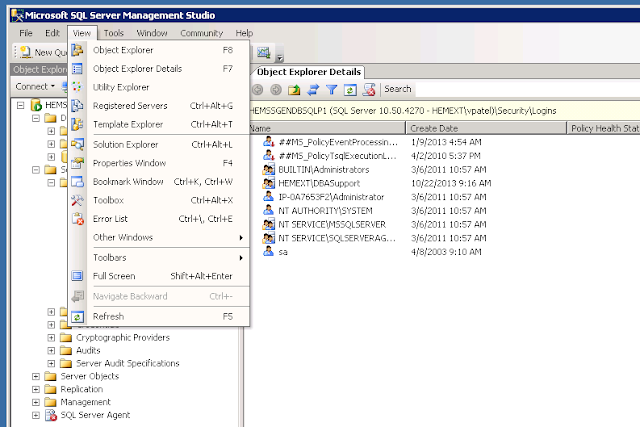
3. Select all jobs from Object Explorer Details Windows
4. Right Click on selected jobs and then select Script Job As -> Create To -> New Query window

5. Now copy script from new query window and then paste it to new server.
6. Before executing scripts you need to make sure followings.
Let me know if you have any comment.
2. Then click on View on menu bar and then select Object Explorer Details
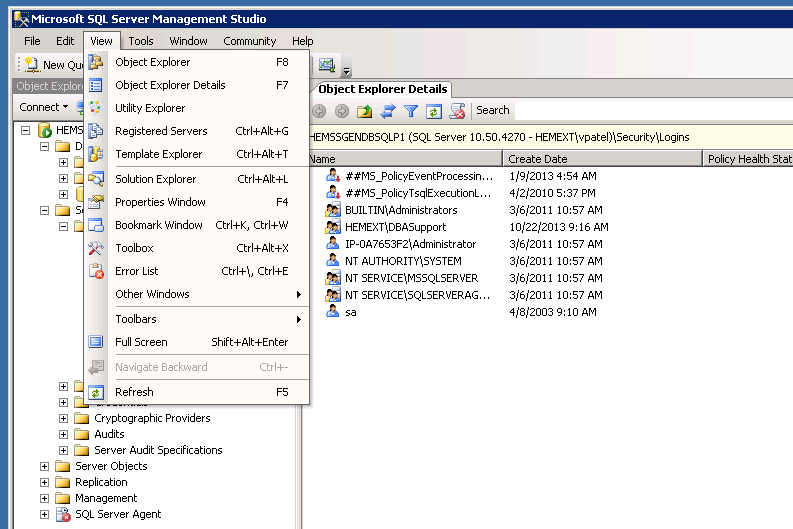
3. Select all jobs from Object Explorer Details Windows
4. Right Click on selected jobs and then select Script Job As -> Create To -> New Query window

5. Now copy script from new query window and then paste it to new server.
6. Before executing scripts you need to make sure followings.
- Make sure email operator are exist on new server.
- Make sure SSIS packages are exist on new server.
- Make sure Security Credentials are created on new server.
- Make sure users are present on new server as well.
Let me know if you have any comment.
Friday, June 28, 2013
SQL 2012 - Contained Database
A contained database is a database that is isolated from other databases and from the instance of SQL Server that hosts the database. SQL Server 2012 helps user to isolate their database from the instance in 4 ways.
- Much of the metadata that describes a database is maintained in the database. (In addition to, or instead of, maintaining metadata in the master database.)
- All metadata are defined using the same collation.
- User authentication can be performed by the database, reducing the databases dependency on the logins of the instance of SQL Server.
Requirements of contained databases.
- It is required to enable contained databases on the instance.
- The contained database needs to be added to the connection string or specified when connecting via SQL Server Management Studio
Partial containment is enabled using the CREATE DATABASE and ALTER DATABASE statements or by using SQL Server Management Studio.
How to configure contained database:
EXEC SP_CONFIGURE 'show advanced options',1GORECONFIGUREGOEXEC SP_CONFIGURE 'contained database authentication',1GORECONFIGUREGOUSE [master]GOCREATE DATABASE [ContainedDB] CONTAINMENT = PARTIAL
Found some disadvantages of Contained Database:
Connection strings
Connection strings to a contained database must explicitly specify the database in the connection string. You can no longer rely on the login's default database to establish a connection; if you don't specify a database, SQL Server is not going to step through all the contained databases and try to find any database where your credentials may match.
Cross-db queries
Even if you create the same user with the same password in two different contained databases on the same server, your application will not be able to perform cross-database queries. The usernames and passwords may be the same, but they're not the same user. The reason for this? If you have contained databases on a hosted server, you shouldn't be prevented from having the same contained user as someone else who happens to be using the same hosted server. When full containment arrives (likely in the version after SQL Server 2012), cross-database queries will absolutely be prohibited anyway. I highly, highly, highly recommend that you don't create server-level logins with the same name as contained database users, and try to avoid creating the same contained user name in multiple contained databases.
Synonyms
Most 3- and 4-part names are easy to identify, and appear in a DMV. However if you create a synonym that points to a 3- or 4-part name, these do not show up in the DMV. So if you make heavy use of synonyms, it is possible that you will miss some external dependencies, and this can cause problems at the point where you migrate the database to a different server. I complained about this issue, but it was closed as "by design." (Note that the DMV will also miss 3- and 4-part names that are constructed via dynamic SQL.)
Password policy
If you have created a contained database user on a system without a password policy in place, you may find it hard to create the same user on a different system that does have a password policy in place. This is because the
CREATE USER syntax does not support bypassing the password policy. I filed a bug about this problem, and it remains open. And it seems strange to me that on a system with a password policy in place, you can create a server-level login that easily bypasses the policy, but you can't create a database user that does so - even though this user is inherently less of a security risk.
Collation
Since we can no longer rely on the collation of tempdb, you may need to change any code that currently uses explicit collation or
DATABASE_DEFAULT to use CATALOG_DEFAULT instead. See this BOL article for some potential issues.
IntelliSense
If you connect to a contained database as a contained user, SSMS will not fully support IntelliSense. You'll get basic underlining for syntax errors, but no auto-complete lists or tooltips and all the fun stuff. I filed a bug about this issue, and it remains open.
SQL Server Data Tools
If you are planning to use SSDT for database development, there currently isn't full support for contained databases. Which really just means that building the project won't fail if you use some feature or syntax that breaks containment, since SSDT currently doesn't know what containment is and what might break it.
ALTER DATABASE
When running an
ALTER DATABASE command from within the context of a contained database, rRather than ALTER DATABASE foo you will need to use ALTER DATABASE CURRENT - this is so that if the database is moved, renamed, etc. these commands don't need to know anything about their external context or reference.
A few others
Some things you probably shouldn't still be using but nonetheless should be mentioned in the list of things that aren't supported or are deprecated and shouldn't be used in contained databases:
- numbered procedures
- temporary procedures
- collation changes in bound objects
- change data capture
- change tracking
- replication
Monday, April 15, 2013
SQL Server - Interview Questions and Answers . (Updated in 2018)
SQL Server DBA interview questions and answers..
Lets help other dba to find their dream job.
- Tell me about your self. - Most of the time, this will be the first questions in your interview.
- What is a page in sql server? - The fundamental unit of data storage in SQL Server is the page. The disk space allocated to a data file (.mdf or .ndf) in a database is logically divided into pages numbered contiguously from 0 to n. Disk I/O operations are performed at the page level. That is, SQL Server reads or writes whole data pages. In SQL Server, the page size is 8 KB. This means SQL Server databases have 128 pages per megabyte. Each page begins with a 96-byte header that is used to store system information about the page. This information includes the page number, page type, the amount of free space on the page, and the allocation unit ID of the object that owns the page. Data rows are put on the page serially, starting immediately after the header. A row offset table starts at the end of the page, and each row offset table contains one entry for each row on the page. Each entry records how far the first byte of the row is from the start of the page. The entries in the row offset table are in reverse sequence from the sequence of the rows on the page.

What is an extent in sql server? - Extents are a collection of eight physically contiguous pages and are used to efficiently manage the pages. All pages are stored in extents. Extents are the basic unit in which space is managed. An extent is eight physically contiguous pages, or 64 KB. This means SQL Server databases have 16 extents per megabyte.
To make its space allocation efficient, SQL Server does not allocate whole extents to tables with small amounts of data. SQL Server has two types of extents:
Uniform extents are owned by a single object; all eight pages in the extent can only be used by the owning object.
Mixed extents are shared by up to eight objects. Each of the eight pages in the extent can be owned by a different object. A new table or index is generally allocated pages from mixed extents. When the table or index grows to the point that it has eight pages, it then switches to use uniform extents for subsequent allocations. If you create an index on an existing table that has enough rows to generate eight pages in the index, all allocations to the index are in uniform extents.
What is the relation between page and extent? - read above answer.
How many services are installed when you install sql server first time? - SQL SERVICES, SQL AGENT SERVICE, SQL BROWSER SERVICE, SQL SERVER ACTIVE DIRECTORY HELP, SQL SERVER VSS WRITER.
What doesn SQL Browser Service do? - The SQL Server Browser program runs as a Windows service. SQL Server Browser listens for incoming requests for Microsoft SQL Server resources and provides information about SQL Server instances installed on the computer. SQL Server Browser contributes to the following actions:
Browsing a list of available servers
Connecting to the correct server instance
Connecting to dedicated administrator connection (DAC) endpoints
What types of indexes are available in SQL Server? Cluster Index and Non Cluster Index.
What is the difference between Cluster and Non-Clustered index?
Why do you need Non-Clustered Index?
What is covering index? Why do you need Covering Index?
What is Composite Index? Why do we need it?
Difference between Composite Index and Covering Index.
What was your backup strategies?
What is the difference between Full backup vs Differential backup?
What is tail-log backup? When do we use tail-log backup?
What is the difference between rebuild index and reorg index?
When do we rebuild index and reorg index?
What is sql statistics and what kind of information it contains?
When do you need to update statistics?
How do you find out statistics is not updated?
Which DMV finds the missing indexes?
Is it good idea to add all recommended missing indexes?
How do you find out Indexes are fragmented? How do you fix this issue?
How do you find out the length of the column?
How do you find out BLOB object column length?
What is your DR strategies?
What is the difference between Mirroring and LogShipping?
What types of mirroring are available?
What is the difference between Asynchronous and synchronous mirroring?
How do you setup LogShipping in your environment?
Have you ever worked with replication? What types of replications are available?
How do you setup replication if database is really big?
How does replication works? exp: Transactional Replication.
How do you solve latency issue in sql server?
Tell us about some DBCC commands you use in daily work.
Tell us about some DMV commands you use in daily work.
Have you ever worked on clustered environment? What is the difference between active and passive clustered?
How big was your clustered environment?
What is the difference between 2005 and 2008 clustered?
Can you install sql server from remote machine in cluster?
Have you ever add SAN in clustered? if Yes, what are the steps to add SAN in clustered?
Have you ever add or move Quorum drive? What are the steps to do it?
What are the steps to upgrade SQL on clustered environment?
What is minimum requirements before installing SQL on Cluster environment?
What is Index Padding and Fill Factor?
What would you do if you want to update statistics and db is really huge?
What is Sample rows or percentage in Update Statistics?
Have you ever worked with reporting service? Explain your role in that.
How to migrate reports from one server to another server?
How to find out error in reporting server? - Reporting service has their own log file.
Have you ever worked with SSIS? explain your role in that.
How many ways you can deploy SSIS packages?
What is the difference between File System and SQL Server deployment?
How to migrate packages from File System to File system and MSDB to MSDB?
If you are doing replication of one database and if you do rebuild index on primary server does secondary server will follow same?
How to move one table from one disk to another disk when there is a space issue on database and you don't have any other data files?
How to add data or log file when database is in Mirroring, Log-Shipping or AlwaysOn?
How to start SQL when WSFC is offline? https://www.mssqltips.com/sqlservertip/4917/recover-wsfc-using-forced-quorum-for-sql-server-alwayson-availability-group/
How to upgrade SQL Server when database is in AlwaysOn?
How to troubleshoot AlwaysOn performance or not synchronizing issue?
Which SQL 2016 features you have been using in your current environment?
What is the difference in SQL 2012 and 2014/2016 AlwaysOn Availibility Group?
What is the difference between SQL 2012 and SQL 2016 installation?
What is SQL Server R Service?

Sunday, February 24, 2013
Using Distributed Replay to load test your SQL Server–Part 2
After we have configured the Distributed Replay as explained in the previous post, we can use the Distributed Replay environment to create the load on the SQL Server.

The screenshot above shows that an error occurred. The important part is “…and that the console user has the proper permissions to access the controller service”
The login account is sqladmin on the server. It can be checked using “whoamI” command using the command prompt on ServerN1. The system event log on ServerN1 says that

BTW, these steps might seem familiar – we had used them in the first post for the service account itself. Once the permission issue is fixed, the preprocess command generated 2 files within “C:\DRPreProcess” folder.
At the same time open a profiler trace and connect to target server which is ServerN2\SQL2012 collect profiler trace. Then you can compare the trace file from source server and trace file from target server and check some query performance. You can refer to this article for more details.
That’s it! Hopefully we have covered the basics of Distributed Replay and how you can use it to reproduce a workload on a test system. Please leave your feedback and questions in the comments area below!
Data Collection from Source Server
We need to collect some data from the main production server and then we can use the collected data to create load on the new SQL Server. To do this, follow the steps below.- Create “C:\DRDemo” folder on the controller (which is ServerN1 in our test.)
- Open SQL Server 2012 Profiler Trace utility on ServerN1
- Select File –> New Trace –> Connect to ServerN1. Note that we are using ServerN1 to simulate the workload as well for this test. In the real world we would be capturing the trace from a server which is currently in production.
- Select the TSQL – Replay template within “Use the template” drop down menu and run the trace.
- Run “C:\DRDemo\StartWorkload.cmd” to bring some load to SQL Server 2008 R2 system. The system is not production so the script is used to create some load on the production.
- After the script is completed, save the trace file within “C:\DRDemo”. For the example it is “C:\DRDemo\ServerN1_SQL2008R2_Trace.trc”.
- Now the trace from source server is ready.
Preprocess the source Trace file
The source trace file will be used to prepare files which are used by distributed clients to create load on the new SQL Server. Run the command below using command prompt on the controller (ServerN1) to prepare the files for the distributed clients.c:\DRDemo>dreplay preprocess -i "C:\DRDemo\ServerN1_SQL2008R2_Trace.trc" -d "C:\DRPreProcess"

The screenshot above shows that an error occurred. The important part is “…and that the console user has the proper permissions to access the controller service”
The login account is sqladmin on the server. It can be checked using “whoamI” command using the command prompt on ServerN1. The system event log on ServerN1 says that
Description:To fix this issue, we need to the steps below on ServerN1:
The application-specific permission settings do not grant Local Activation permission for the COM Server application with CLSID {6DF8CB71-153B-4C66-8FC4-E59301B8011B} and APPID {961AD749-64E9-4BD5-BCC8-ECE8BA0E241F} to the user AYSQLTEST\sqladmin SID (S-1-5-21-2826735731-136765897-3671058344-1125) from address LocalHost (Using LRPC). This security permission can be modified using the Component Services administrative tool.
- ServerN1 - Run and type dcomcnfg and Component Services will be opened.
- Find DReplayController (Console Root –> Component Services –> Computers –> My Computer – >DCOM Config -> DReplayController)
- Open the properties of DReplayController and select Security tab
- Edit “Launch and Activation Permissions” and grant “sqladmin” domain user account “Local Activation” and “Remote Activation” permissions.
- Edit “Access Permissions” and grant “sqladmin” domain user account “Local Access” and “Remote Access”.
- Restart controller and client services like below
NET STOP "SQL Server Distributed Replay Controller"
NET STOP "SQL Server Distributed Replay Client"
NET START "SQL Server Distributed Replay Controller"
NET START "SQL Server Distributed Replay Client" - Run the command again:
dreplay preprocess -i "C:\DRDemo\ServerN1_SQL2008R2_Trace.trc" -d "C:\DRPreProcess"

BTW, these steps might seem familiar – we had used them in the first post for the service account itself. Once the permission issue is fixed, the preprocess command generated 2 files within “C:\DRPreProcess” folder.
Replay against SQL Server 2012 using clients
Preprocess phase has been completed. Controller will take 2 files “ReplayEvents.irf”, “TraceStats.xml” and copy them to the clients (ServerN1,ServerN3) and replay them on the clients against target server which is SQL Server 2012 called ServerN2\SQL2012. Here is the command to do so:dreplay replay -s ServerN2\sql2012rc0 -w ServerN1,ServerN3 -f 10 -o -d "C:\DRPreProcess"The -o parameter will save the trace output within “C:\Program Files (x86)\Microsoft SQL Server\110\Tools\DReplayClient\ResultDir”
At the same time open a profiler trace and connect to target server which is ServerN2\SQL2012 collect profiler trace. Then you can compare the trace file from source server and trace file from target server and check some query performance. You can refer to this article for more details.
That’s it! Hopefully we have covered the basics of Distributed Replay and how you can use it to reproduce a workload on a test system. Please leave your feedback and questions in the comments area below!
Using Distributed Replay to load test your SQL Server–Part
Have you decided to migrate SQL Server to a newer version? Would you like to test the load on the new SQL Server? How can you create a load on the new SQL Server? Do you need to develop a multi threaded application to simulate load on SQL Server? Using a new feature of SQL Server 2012, called Distributed Replay, it is so simple to simulate load on a SQL Server for testing purposes.
Before proceeding, it may be useful to review what Distributed Replay is all about.

For your information, here are the installation folders for each server:
ServerN1: C:\Program Files (x86)\Microsoft SQL Server\110\Tools\DReplayClient and
C:\Program Files (x86)\Microsoft SQL Server\110\Tools\DReplayController
ServerN2: Nothing installed related to Distributed Replay because those features has not been selected.
ServerN3: C:\Program Files (x86)\Microsoft SQL Server\110\Tools\DReplayClient
After setting new service accounts "SQL Server Distributed Replay Controller" and "SQL Server Distributed Replay Client" services has been restarted using the command prompt on ServerN1 and ServerN3 like below.
ServerN1:




Edited and posted by Arvind Shyamsundar, MSPFE Editor.
Before proceeding, it may be useful to review what Distributed Replay is all about.
Installation
There should be one distributed replay controller and between 1 and 16 distributed replay clients. Distributed Replay Controller and Distributed Replay Client can be installed separately or together on any server. If you decide to install Distributed Replay on a Server, in addition to this Management Tools should be installed to the same SQL Server because dreplay.exe file (Distributed Replay Administration Tool) comes with the client tools as highlighted below.
Test Setup
We are using the following computers for our test.- ServerN1: this will be our controller; it has the following components installed:
- Distributed Replay Client
- Distributed Replay Controller
- Management Tools
- SQL Server 2008 R2 Database Engine Services
- ServerN2: this will be our target system. It has SQL Server 2012 Database Engine Services installed.
- ServerN3: this is a Distributed Replay Client
For your information, here are the installation folders for each server:
ServerN1: C:\Program Files (x86)\Microsoft SQL Server\110\Tools\DReplayClient and
C:\Program Files (x86)\Microsoft SQL Server\110\Tools\DReplayController
ServerN2: Nothing installed related to Distributed Replay because those features has not been selected.
ServerN3: C:\Program Files (x86)\Microsoft SQL Server\110\Tools\DReplayClient
Service Accounts
Separate service accounts can be configured for “Distributed Replay Client” and “Distributed Replay Controller”. For our example “sqlservice” domain user account has been used.After setting new service accounts "SQL Server Distributed Replay Controller" and "SQL Server Distributed Replay Client" services has been restarted using the command prompt on ServerN1 and ServerN3 like below.
ServerN1:
NET STOP "SQL Server Distributed Replay Controller"ServerN3:
NET STOP "SQL Server Distributed Replay Client"
NET START "SQL Server Distributed Replay Controller"
NET START "SQL Server Distributed Replay Client"
NET STOP "SQL Server Distributed Replay Client"After the restart, check the last log file of the Distributed Replay Client within the folder “C:\Program Files (x86)\Microsoft SQL Server\110\Tools\DReplayClient\Log”. You may find that an error “Failed to connect controller with error code 0x80070005” is reported. Error code 0x80070005 means “Access is denied”.
NET START "SQL Server Distributed Replay Client"

Remediation: ServerN1
- ServerN1 - Start -> Run and type dcomcnfg and Component Services will be opened.
- Find DReplayController (Console Root –> Component Services –> Computers –> My Computer –> DCOM Config -> DReplayController)
- Open the properties of DReplayController and select Security tab
- Edit “Launch and Activation Permissions” and grant “sqlservice” domain user account “Local Activation” and “Remote Activation” permissions.
- Edit “Access Permissions” and grant “sqlservice” domain user account “Local Access” and “Remote Access”.
- Add “sqlservice” domain user account within “Distributed COM Users” group.
- Restart controller and client services like below
NET STOP "SQL Server Distributed Replay Controller"
NET STOP "SQL Server Distributed Replay Client"
NET START "SQL Server Distributed Replay Controller"
NET START "SQL Server Distributed Replay Client" - Check the Distributed Replay Client log file and see the message “Registered with controller ServerN1”

ServerN3
- Restart client service like below
NET STOP "SQL Server Distributed Replay Client"
NET START "SQL Server Distributed Replay Client" - Check the Distributed Replay Client log file and see the message can be seen like “Failed to connect controller with error code 0x800706BA”. ServerN3 client may not connect to controller which is running on ServerN1.

Firewall Exceptions
As per this link, we need to set the firewall exceptions correctly. Apply the steps below on each remote Distributed Replay Client:- Open Windows Firewall with Advanced Security
- Click Inbound Rules – Right click and select New Rule
- Rule Type: Select Program and click next
- Program: Select “This program path” and browse “C:\Program Files (x86)\Microsoft SQL Server\110\Tools\DReplayClient\DReplayClient.exe” and click next
- Action: Select “Allow the connection” and click next
- Profile: Keep all selected such as Domain, Private and Public (usually Domain should be enough) and click next
- Name: Type “Allow Distributed Replay Client” and click finish
- Open Windows Firewall with Advanced Security
- Click Inbound Rules – Right click and select New Rule
- Rule Type: Select Program and click next
- Program: Select “This program path” and browse “C:\Program Files (x86)\Microsoft SQL Server\110\Tools\DReplayController\DReplayController.exe” and click next
- Action: Select “Allow the connection” and click next
- Profile: Keep all selected such as Domain, Private and Public (usually Domain should be enough) and click next
- Name: Type “Allow Distributed Replay Controller” and click finish
- Restart client service like below
NET STOP "SQL Server Distributed Replay Client"
NET START "SQL Server Distributed Replay Client" - Check the Distributed Replay Client log file and see the message “Registered with controller ServerN1”. ServerN3 client will connect to controller properly.

Conclusion
At this stage, our Distributed Replay clients are setup and working correctly. In the next part of this article, we will show you how to use the DREPLAY utility to replay a workload on the server.Edited and posted by Arvind Shyamsundar, MSPFE Editor.
SQL 2012 - SQL Server Distributed Replay
SQL Server Distributed Replay
Benefits of Distributed Replay
Benefits of Distributed Replay
Similar to SQL Server Profiler, you can use Distributed Replay to replay a captured trace against an upgraded test environment. Unlike SQL Server Profiler, Distributed Replay is not limited to replaying the workload from a single computer.
Distributed Replay offers a more scalable solution than SQL Server Profiler. With Distributed Replay, you can replay a workload from multiple computers and better simulate a mission-critical workload.
The Microsoft SQL Server Distributed Replay feature can use multiple computers to replay trace data and simulate a mission-critical workload. Use Distributed Replay for application compatibility testing, performance testing, or capacity planning.
When to Use Distributed Replay
Distributed Replay offers a more scalable solution than SQL Server Profiler. With Distributed Replay, you can replay a workload from multiple computers and better simulate a mission-critical workload.
The Microsoft SQL Server Distributed Replay feature can use multiple computers to replay trace data and simulate a mission-critical workload. Use Distributed Replay for application compatibility testing, performance testing, or capacity planning.
When to Use Distributed Replay
SQL Server Profiler and Distributed Replay provide some overlap in functionality.
You may use SQL Server Profiler to replay a captured trace against an upgraded test environment. You can also analyze the replay results to look for potential functional and performance incompatibilities. However, SQL Server Profiler can only replay a workload from a single computer. When replaying an intensive OLTP application that has many active concurrent connections or high throughput, SQL Server Profiler can become a resource bottleneck.
Distributed Replay offers a more scalable solution than SQL Server Profiler. Use Distributed Replay to replay a workload from multiple computers and better simulate a mission-critical workload.
Distributed Replay Concepts
The Distributed Replay administration tool, controller, and client can be installed on different computers or the same computer. There can be only one instance of the Distributed Replay controller or client service that is running on the same computer.
The following figure shows the SQL Server Distributed Replay physical architecture:

You may use SQL Server Profiler to replay a captured trace against an upgraded test environment. You can also analyze the replay results to look for potential functional and performance incompatibilities. However, SQL Server Profiler can only replay a workload from a single computer. When replaying an intensive OLTP application that has many active concurrent connections or high throughput, SQL Server Profiler can become a resource bottleneck.
Distributed Replay offers a more scalable solution than SQL Server Profiler. Use Distributed Replay to replay a workload from multiple computers and better simulate a mission-critical workload.
Distributed Replay Concepts
The following components make up the Distributed Replay environment:
- Distributed Replay administration tool: A console application, DReplay.exe, used to communicate with the distributed replay controller. Use the administration tool to control the distributed replay.
- Distributed Replay controller: A computer running the Windows service named SQL Server Distributed Replay controller. The Distributed Replay controller orchestrates the actions of the distributed replay clients. There can only be one controller instance in each Distributed Replay environment.
- Distributed Replay clients: One or more computers (physical or virtual) running the Windows service named SQL Server Distributed Replay client. The Distributed Replay clients work together to simulate workloads against an instance of SQL Server. There can be one or more clients in each Distributed Replay environment.
- Target server: An instance of SQL Server that the Distributed Replay clients can use to replay trace data. We recommend that the target server be located in a test environment.
The following figure shows the SQL Server Distributed Replay physical architecture:

Subscribe to:
Comments (Atom)